
As more businesses look to integrate AI into their workflows, one technique is standing out for its ability to deliver highly accurate and context-aware responses: Retrieval-Augmented Generation (RAG). By combining large language models like GPT-4 with your own internal data, RAG enables scalable, intelligent applications that are grounded in real knowledge-not just training data.
But what does it take to build a RAG system? And how do modern tools like Next.js, Supabase, and OpenAI fit into the picture?
In this article, we'll look at:
- What RAG is and why it matters
- How the RAG pipeline works
- Key benefits for your business
- The modern tech stack to bring it all together
Whether you're building AI for customer support, internal knowledge search, or custom interfaces, this is your roadmap to building a RAG-powered solution.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is a technique that enhances language model outputs with real-world data from your own knowledge sources. While LLMs like GPT-4 are powerful, they come with limitations:
- They can't access private or up-to-date data (e.g., internal documents, recent updates).
- They sometimes “hallucinate” or produce inaccurate information.
- They lack real-time knowledge of your business context.
RAG solves this by augmenting generation with retrieval, injecting relevant, factual context into the model's prompts.
How RAG Works
Here's a simplified breakdown of the RAG workflow:
1. User Asks a Question
Example: “How do I reset my product to factory settings?”
2. Embed & Search for Relevant Content
The query is converted into a vector and compared against pre-embedded documents (manuals, FAQs, etc.) in a vector database (like Supabase + pgvector).
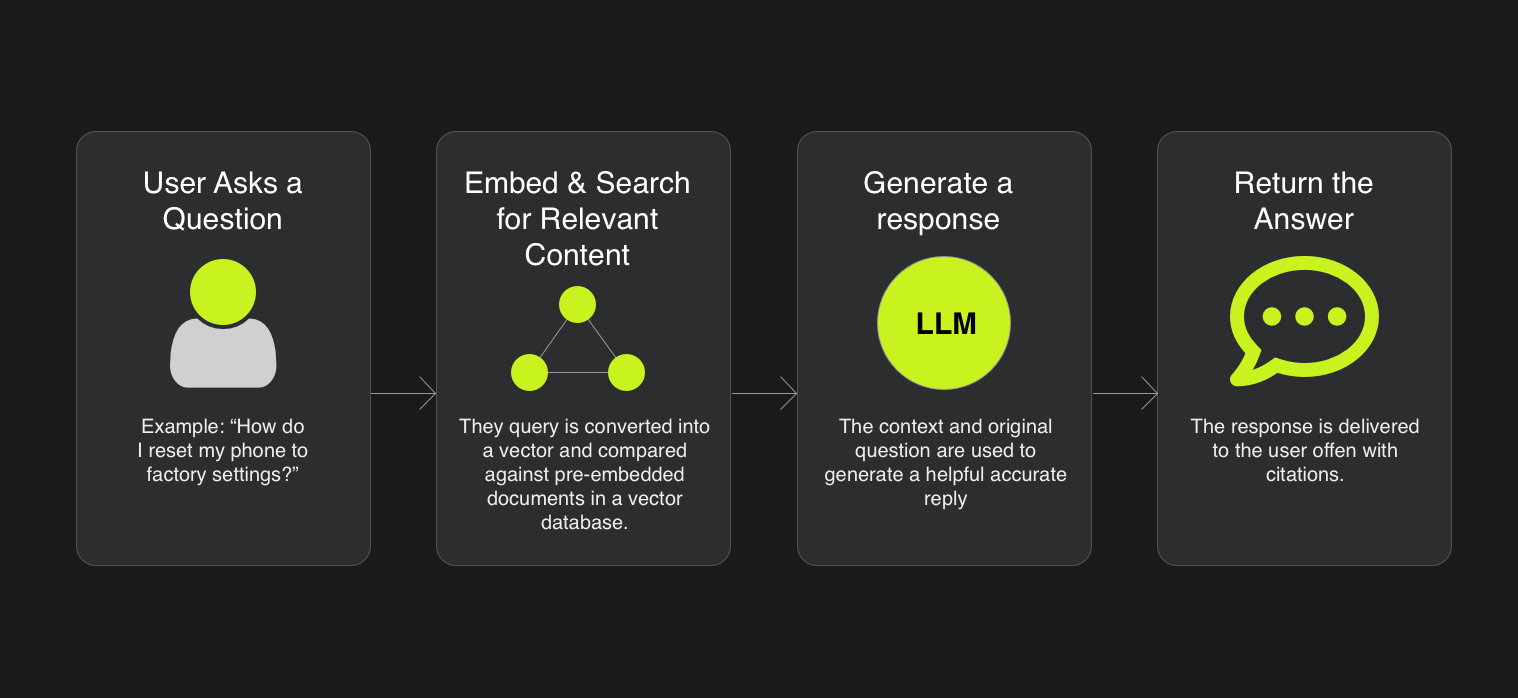
3. Generate a Response
The context and original question are sent to the language model (e.g., GPT-4) to generate a helpful, accurate reply.
4. Return the Answer
The response is delivered to the user-often with citations for transparency.
Why RAG Matters for Your Business
Unlike traditional chatbots that rely on keyword matching or scripted flows, RAG systems are intelligent, dynamic, and easy to keep up-to-date. Here's why RAG is a game-changer:
-
More Accurate, Contextual Responses
RAG uses your actual data-support docs, product manuals, internal wikis-to generate fact-based, domain-specific answers.
-
Saves Time for Users and Teams
Customers get quick, self-serve support.
Employees find answers faster, reducing repetitive questions and onboarding friction.
-
Cost-Effective Scaling
Automate routine queries without expanding your team or retraining models. Your support and search scale with your data.
-
Greater Trust and Transparency
Show users where answers come from. RAG responses can be backed by citations, helping build confidence-especially in regulated industries.
-
Easy to Maintain
Want to update a policy? Just update your documents-no need to retrain a model.
-
Fast Time-to-Value
With modern tools like OpenAI, Supabase, and Next.js, you can go from prototype to production in weeks-not months.
-
Competitive Edge
Adopting AI tools like RAG today sets you apart with smarter support, better user experiences, and leaner operations.
The Modern Tech Stack for RAG: Next.js + OpenAI + Supabase
You don't need a dedicated ML team or complex infrastructure to build a RAG app. Here's how three modern tools come together to form a powerful stack:
Next.js – Full-Stack Foundation
Next.js is a full-stack framework that combines frontend and backend capabilities in one seamless environment. You can build interactive UIs for chat or search, while handling backend tasks like embeddings, retrieval, and OpenAI integration through API routes.
With features like Server Components and Edge Functions, Next.js is optimized for performance and low latency. It also offers developer-friendly tooling that scales easily, especially when deployed on Vercel.
OpenAI – Language Intelligence
OpenAI offers two essential APIs that simplify building AI-powered applications. The Embeddings API transforms text into vector representations, enabling powerful semantic search capabilities. This allows your app to understand and match meaning, not just keywords.
The Chat API, such as GPT-4, takes the retrieved context and generates coherent, helpful responses. There's no need for custom model training-just connect the APIs and start building intelligent features right away.
Supabase – Vector-Aware Backend
Supabase is a modern backend platform that combines the reliability of PostgreSQL with a suite of powerful, developer-friendly features. It includes native vector search via `pgvector`, making it ideal for semantic document retrieval in AI applications. Built-in authentication provides secure user access control, while Realtime and Storage features support file uploads and live data updates with ease.
With its seamless integration of database, auth, real-time functionality, and storage, Supabase is a strong choice for developers building scalable, intelligent applications quickly and efficiently.
Putting It All Together: The RAG Flow
the user begins by submitting a natural language question through a Next.js-powered frontend interface. This provides a smooth, interactive user experience for entering queries.
Once the question is submitted, a Next.js API route sends it to OpenAI's Embedding API, where the text is transformed into a vector-a mathematical representation of its meaning. This allows for semantic search based on the intent behind the question.
The vectorized query is then passed to Supabase, which performs a similarity search against pre-stored document vectors. This step retrieves the most relevant content chunks from your knowledge base or database.
The backend then combines the original question with the retrieved context and sends both to OpenAI's Chat API (e.g., GPT-4). The language model uses this context to generate a clear, relevant, and grounded response.
Finally, the AI-generated answer is returned to the frontend and displayed to the user. The entire process happens within seconds, enabling fast, scalable, and accurate interactions grounded in your organization's data.
Fast, simple, flexible, and scalable-efficient queries and rendering deliver quick responses; managed services reduce setup and maintenance; it's easy to add new features like uploads, auth, or analytics; and you can build your MVP quickly, then scale when you're ready.

Retrieval-Augmented Generation is no longer just a research concept-it's a practical, production-ready solution. With the right stack, businesses of all sizes can build intelligent, trustworthy AI applications that stay grounded in real data.
If you're looking to bring AI into your support workflows, internal tools, or user-facing apps, RAG is the future-ready approach-and tools like Next.js, Supabase, and OpenAI make it easier than ever to get started.
The tech stack is also flexible and can be adjusted to suit your sepecific needs however I've found that this tooling makes it easy to get up and running quickly
